Here's an example of what tools you can use to extract and load data.
Let's say you have events data from your Amplitude account, tracking events on your website, and you want to extract and load that data into a table in snowflake.
Pre-reqs:
-Amplitude Account & API Keys
-AWS Account, Access Keys or ARN & S3 Bucket Name
-Snowflake Account
AIRBYTE :
1) Set up connection with Source = Amplitude and Destination = Amazon 3S
--This is where you'll need your Amplitude and AWS keys and S3 Bucket Name

2) Sync Data
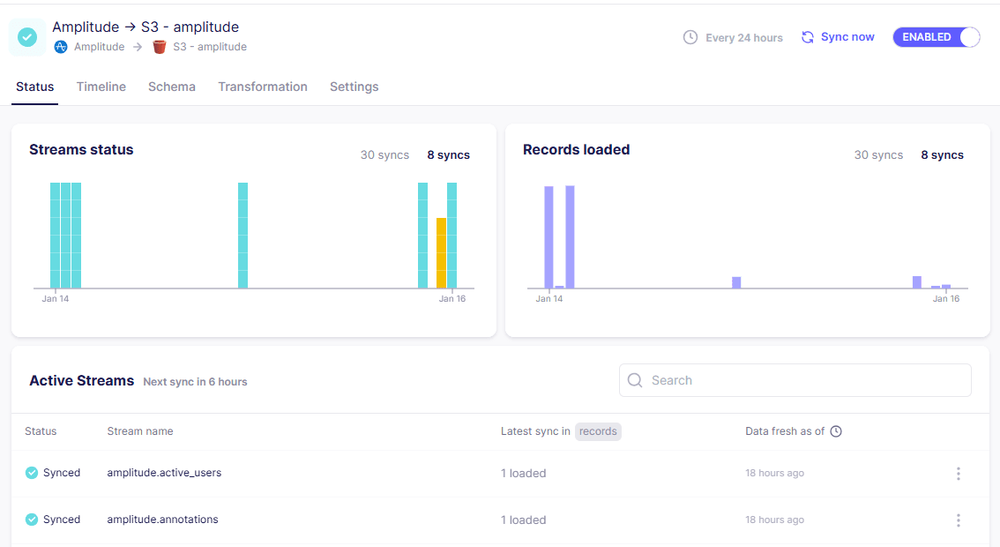
End Result: all amplitude files are visible in s3 bucket (inherit folder/file structure via airbyte)
--Files in S3 bucket are parquet files
Did You Know? Airbyte can be replaced with a Python script where you pass your Amplitude and AWS keys to extract the data from source to destination.
SNOWFLAKE :
1) Define a file format to read and parse the parquet files
see file format docs for more options:https://docs.snowflake.com/en/sql-reference/sql/create-file-format
Did You Know? Snowflake supports structured (ie. CSV) and unstructured (JSON, Parquet, XML, and more) file formats
2) Create Stage for S3 authentication
The stage acts as the bridge between our snowflake application and our AWS bucket. This is needed for loading but no data is loaded just yet.
Did You Know? Directory = (enable = true) allows you to view directory structure within snowflake (can see files but cannot open)
3) Create table from template
Using infer_schema, we can read a single file from the stage to infer it's columns etc and create a template for loading the rest of the data into the table
4) Load data into table
Use wild card (.*\parquet) to pull all parquet files in defined directory
5) Query freshly loaded data!
End Result: You'll see the parquet data has been parsed to columns and all parquet files in the directory have been loaded to the table in snowflake